頭蓋骨振動誘発眼振検査って知ってますか? - The Skull Vibration-induced Nystagmus Test(SVINT) -
どうも、6ヶ月に1回程度しか更新しないブログです。
いつもいつも、しょうもない記事ですみません。
頭蓋骨振動誘発眼振検査って知ってますか?
あまり聞かないですよね。頭蓋骨振動誘発眼振検査は Skull Vibration-induced Nystagmus Test (SVINT)で検索するとそれなりに論文がヒットします。2年ほど前にはシステマティックレビューも出ていますね!
とても簡単にまとめると、前庭の非対称など異常を検出する検査のようです。
そういえば、何気に前庭やめまいに関しての記事を以前にも書いているので、よければご覧ください。
この記事を書いた時(5-6年前)は勉強不足でした。
おそらく、このSVINTが非侵襲かつ簡単かつ最も信頼性の高い前庭検査だと思います。この検査は高い周波数帯の前庭動眼反射を検査するための検査です。
<方法>
・SVINTは座っている患者に対して行います。
・フレンツェルメガネ or ビデオ眼振計のもとで観察
・対象者は、目を大きく開いて瞬きをできるだけ少なくして頂きます。また正中線での視線を維持し、真っ直ぐ前を見続ける必要があります。
・振動刺激部位:乳様突起部(外耳の後ろ)
・振動(Hz): おおよそ 100 Hz
・振動刺激時間:10 sec
・振動の振幅の範囲は 0.02 ~ 0.2 mm、加速度の範囲は 10 ~ 20 m/s2
・振幅(mm):0.02 ~ 0.2 mm
おおよそ、50 Hzで加速度は、10.3 m/s2、60 Hzでは11.7 m/s2なので、厳密に100 Hzでなくとも大丈夫そうです。アメリカの研修で使用していたバイブレーション機器も90 Hzのものを使用しおりました。おそらくですが、最も一般的にリハビリ室にあるバイブは60 Hzなので十分可能かと思います。
ちなみに、ポータブル電マのこちら(下記)も最大 9000 Rpm(150 Hz位)なので、加速度が14.8 m/s2、振幅が最小 0.03 mmなので、速度を少し落とせば十分使用できそうですね。個人的にはポータブルなのでこちらの方が使いやすいかもです。
SVINTの陽性所見ですが、振動刺激による眼振( vibration-induced nystagmus:VIN )です。しかし、厳格に陽性とするのであれば、以下のような所見が必要なようです。
1. VINは振動刺激により開始、刺激を止めると停止し、二次的な反転を示さず、両方の乳様突起で一定で、同じ方向に拍動する。
(例えば、VINが右乳様突起で右方向に拍動し、左乳様突起で左方向に拍動することは有意ではない: 検査は陰性である)
2. slow-phase velocity (SPV) が 2.5°/s 以上である.
3. 再現可能であり、2 つの連続したテストで同一または類似
2番はビデオ眼振計が必要なので臨床場面では現実的ではないですね。フレンツェル眼鏡を使用して、眼振を確認することが望ましいかと思います。
眼振の方向は基本的には、患側耳の検査で眼振は検測に起こります。
一部、異なる方向に眼振が起こる疾患がありますがsuperior canal dehiscence syndrome (SCD:上半規管裂隙症候群)のは、眼振は患側に起こるようですが、SCDは聴覚に異常がでたりするようですし、稀な疾患なので、そこまで考えすぎる必要はないかと思います。
SVINTのYoutube動画がありましたので載せておきます。
最後に、頭蓋骨振動誘発眼振検査(SVINT)は、高周波の前庭非対称性の優れたマーカーであり、観察された眼振は、耳石によるものよりも耳管からの方が関連性が高くなるようです。
https://takuma-ai.hatenablog.com/entry/2021/02/02/161819
自転車運転教室に参加させていただきました。

自転車運転教室に参加させていただきました。
個人的にはとても良い経験になりましたし、重要な分野の1つだと考えるようになりました。必要な分野ではありますし、求めている方々も多くいらっしゃるでしょう。何となく感じたことをだらだらと書いてみました。
ヤフーニュースのコメントであったように、一般的には高齢者の自転車運転は危険だと簡単に予想できます。何をもって危ないかという評価をする必要がありますが、自動車を運転する成人は、"あの自転車に乗っている高齢者は危ないなー"と思った事があるかと思います。
こんなコメントもありましたよ↓↓


その危ないだと中高生の運転も大概危ないのですが、高齢者が転倒した場合、ほとんどの場合は骨折や硬膜下血腫などのリスクが非常に高いです。そこで車の運転手は、危ない年寄りが自転車に乗っていたら、あちらからぶつかってきても車も動いている場合は大抵、車を運転している人の責任になってしまう為、乗らないで欲しいと考えているのではないでしょうか?
認知機能が低下しているから、身体機能が低下しているから、自転車は危険だというお気持ちも分かりますが、どれくらいの認知機能があれば自転車に安全に乗れるのでしょうか?そもそも、その認知機能は何でしょうか?安全と何でしょうか?
シンプルに記憶力が低下しているという症状のみの方で、歩行速度や立ち座りテスト、片足立位などの身体機能検査で十分な機能を有している場合やTMTなどの検査で異常なしの場合は安全でしょうか?私が調べたところでは十分な情報がありませんでした。そのため、何をもって自転車運転がダメという材料がありません。
しかし、片足立位が出来ない、歩行速度も0.1 m/secで頸部の可動域が狭小化している高齢者の場合、(たぶん)自転車運転は難しいですよね。
では、変形性膝関節症や膝蓋骨骨折の既往歴がある患者で可動域制限はありますが、認知機能や注意機能が問題なしの場合はそのまま自転車に乗っても安全でしょうか?サドルの高さの調整が必要かもしれませんし、4輪車や3輪車の方が良いかも知れません。圧迫骨折や腰椎症などがある場合、重心移動が難しいかもしれません。
自転車運転といっても複数の評価項目があり、何をもって大丈夫か安全か、難しいかというカットオフ値のようなものは今の所ありません。今回の龍神整形のような機関が今後は研究を行っていただけると非常に助かります。
(個人的には特徴量抽出をしたいところですし、カットオフ値には少し口うるさい方なので、データがあれば解析してみたい)
そして、もう一つ感じたのは、自転車練習は損と益のバランスやSDMが大切で非常に重要な分野であると感じております。やはり私たちも高齢者が転倒するような事はして欲しくありません。その人の価値は何か、自転車に乗ることは寝ているよりも転倒リスクが高いでしょう。では、遠いところに外出するなということでしょうか?
そういう分けにはいきませんよね。練習して一定の力が身についた場合、そして安全性が担保できる場合は、モビリティを広げることは結果的に移動能力の低下を軽減するという報告もございます。
こちらも
自分が勤務しているところでは、ここまで介入しにくいので、うらやましいと思いつつ、自分のできることをしていきたいなと感じました。
だらだらと乱雑な文をすみません。
数年前(2018年頃)にTwitterのフォロワーが一気に増えた時の話
Twitterのフォロワーが一気に増えた時の話
増えたというより増やしたというべきかもしれません。
行った手順は4つだけ
1. リハ職種の自動応答チャットボット作成
3. Pythonで言葉を指定して自動いいねプログラム作成
4. ラズベリーパイで24時間プログラムを動かす
自動応答チャットボット
今はできるか不明ですが、GoogleのDialogflowとLINEを繋げて自動応答チャットボットを開発しました。筋肉名や整形外科的テストを入力すると自動で教えてくれます。またTwitterのDMやFacebook messengerも同様に自動応答チャットボットにしておりました。
PT Exam Labの友達追加↓ 最近は全く更新していないので、どうなっているか不明です。
![]()
Twitter APIで自動いいね
Twitter社と連絡をとって、パスワードを発行してもらいました。多分、4種類のパスワードがありました(多分50桁くらい)。Pythonである任意の言葉を誰かがTweetしたら、自動でいいねをしにいくというプログラムを作りました。
こんな感じです↓
import os
import csv
import datetime
import time
import tweepy
import schedule
# TwitterのAPIキーを入力
CONSUMER_KEY = ''
CONSUMER_SECRET = ''
ACCESS_TOKEN = ''
ACCESS_TOKEN_SECRET = ''
def get_tweet(search_words):
auth = tweepy.OAuthHandler(CONSUMER_KEY, CONSUMER_SECRET)
auth.set_access_token(ACCESS_TOKEN, ACCESS_TOKEN_SECRET)tweets_list = []
for tweet in api.search(q=search_words, lang="ja", result_type="recent",count=100):
# 日本時間に変換
tweet_time = tweet.created_at + datetime.timedelta(hours=9)tweet_dic = {}
tweet_dic["text"] = tweet.text
tweet_dic["name"] = tweet.user.name
tweet_dic["twitter_id"] = "@" + tweet.user.screen_name
tweet_dic["time"] = tweet_time.strftime("%Y/%m/%d %H:%M:%S")
tweets_list.append(tweet_dic)
return tweets_list
def save_tweet(csv_file_name, tweets_list):
# 指定されたcsvファイルが無ければ新規作成、あれば追記していく
with open(csv_file_name, "a", encoding="utf-8", newline="") as csv_file:
# header を設定
fieldnames = ["ツイート内容", "名前", "Twitter ID", "ツイート日時"]
writer = csv.DictWriter(csv_file, fieldnames=fieldnames)
writer.writeheader()for tweet in tweets_list:
# データの書き込み
writer.writerow({"ツイート内容": tweet["text"],
"名前": tweet["name"],
"Twitter ID": tweet["twitter_id"],
"ツイート日時": tweet["time"]})
def run():
# 保存するcsvファイル名
csv_file_name = "oppi.csv"
# 検索するワード
search_words = "理学療法","理学療法士",try:
print("[DEBUG] Start saving tweet...")# ツイートの取得
tweets_list = get_tweet(search_words)
# csvファイルに書き込み
save_tweet(csv_file_name, tweets_list)print("[DEBUG] Finish!")
except:
print("[DEBUG] Skipped")
if __name__ == "__main__":
run()# 以後3分毎に定期実行
schedule.every(3).minutes.do(run)while True:
schedule.run_pending()
time.sleep(1)
あとは、このプログラムを24時間動かし続けるだけ、、、、
電気代ーーーーーってなりましたので、電気代が最も安い自作PCのようなもので行いました。ラズベリーパイです↓

私が購入した時は、7000円くらいでした。汗
たぶん1週間もしない間に2000-3000人くらいのフォロワーがあったかと思います。ラインの方は1000人くらい友達が増えました。
アンチが面倒臭いのでもうやめましたけど。
PC環境で使っているもの!!
前回は簡単にご紹介いたしました。

上記の環境で使用している物です!

・モニター:Viewsonic 23.8インチ 2台

・モニターアーム : Aamazon basic 2個セット と補強プレート




・マイク

・スピーカー:Creative 2.1ch ステレオ スピーカー

PC環境が完成しました !!!

いかがでしょうか!?
もちろん配線も隠してあります!

廊下から見たPC環境はこちら!
なかなか良いですね!
まず、場所ですが吹き抜けの2階部分に作ったのでモニターの向かい側が壁ではないところが時に良いですね!
一番安い急速充電器です↓ 45wです↓

メッシュWifiの環境:一条工務店の新居用
どうも、新居の完成が近いのですが、ネット環境も見直すことしました。
ハウスメーカーは一条工務店です。一条工務店は全床に床暖房がついているので、下の写真のように金属の板が床に貼られています。そのため、wifiが飛びにくいんですよね。

そこで、Wifiを拡張しようと考えております。
現在、持っている中継機はこちら↓

こちらでも十分速度が出るのですが、中継機と親機を繋ぎ直さないといけないので、安定して速度が速くて繋ぎ直さなくて良い。Wifi環境を作りたかったのです。
そこで、調べているとメッシュWifiなるものがあると情報を入手しました。
メッシュWifiとはWifiの死角をなくすように途切れないように構築するシステムのようです。

しかも、中継機とは異なり、いわゆる親機を2-3個使用するので速度が速く安定しているとのことでした。
Wifiの速度は正味の話、100 Mbps程度あれば十分なので、一般的な速度を保ちつつ安定して通信できるものを探したところ、どうやらTp LinkのDecoシリーズであることがわかってきました。
Decoシリーズのルーターは複数あるのですが、一条工務店の情報ボックスに入るものでなければいけません。いくつかある中でも、コンパクトなDeco m9 plusという商品を購入しました。

↑ Deco m9 plus
この商品の特徴はトライバンドであるということですね。
通常は、2g、5gの電波がありますが、こちらは5gが2つありますので、このルーター同士の通信を安定化させることで安定したwifi環境を作っているということです。
完成が近いので楽しみです。
ランダムフォレストで音声分類してみた。Python - 人工知能・リハビリ・日記・理学療法
英語が読めない療法士必見!! コピペのテクニックで英論文を爆速で読む:Mac版
どうも、英語の論文が読めない先生方は多いと思います。私も得意ではありません。
英語が読めない療法士必見!! コピペのテクニックで英論文を爆速で読む:Mac版
手順は4つ !!
・Clipyをインストール
・pdfから文章コピー
※翻訳したい文を連続でコピーしておく
・shaperを開く
・Clipyからペースト
Clipy
Clipyをコピーしたテキストや画像を保存してくれるアプリです。インストールはこちらからどうぞ!
インストールが完了するとMacbookの右上部分にこのようなマークが出てきます!

このマークをクリックするとCliperが開きます。
こんな感じですね↓

Shaparを開く
shaperはpdfの文章をコピペした時に段落がバラバラになってうまく翻訳できないということが内容に揃えてくれるアプリです。アプリと言ってもWeb上で行うのでサイトを開くだけです。
Shaperを開くとこんな感じ↓

この上の四角の部分にペーストをしたら、下の四角に段落が揃った文章が表示されます。次にDeepLで翻訳というボタンを押せば完了!!
あとは、pdfからコピーしまくったものをペーストしまくって翻訳するだけ!!!
コピーしたものはこのように表示されます。

コピーして翻訳という作業を繰り返すのは面倒臭いですよね。
Clipyを使用して先にコピーだけしておくと楽です!
急速充電器を使っています?
どうも、お疲れ様です。
久しぶりの更新がこんな記事ですみません。
(現在、厚生労働省が推進しているデータマネージャー研究をみっちり受けておりますので、今度、感想を書きたいと思います。)
急速充電器を使っています?
皆様はいかがでしょうか?
私はiPhoneを使用しているのですが、純正の充電器は充電が遅くないですか?
iPhoneの純正充電器は、5 w(watt)です。このwattが大きいと基本的には充電の速度が上がります。
5 wの充電器↓

iPadの充電器を使用しているという方も多いと思います。一般的なiPadの充電器は10wのようです。iPhoneの2倍なので、少し早く充電することができます。これは、iPadをお持ちの方であれば少し実感しているのではないでしょうか?
最近は、GaNという規格というかモノがあり、高いwattの急速充電器が続々と販売されております。しかも、小型です。
近々、戸建ての引き渡しになるので、充電器も質の高いものに変更しようかと考えております。例えばこれ↓
こちらは65w、45wで小型という非常に質の高い充電器です。45wあればmac bookも充電できますし、65wだとmac bookも急速充電の対象となるようです。
USB 3.0では急速充電ができないのでUSB Type-Cをご使用ください。
USB 3.0では、20w程度止まりで急速充電と言ってもそれなりです。
ちなみに、USBケーブルの長さが非常に長いものを使用すると高いwで充電できないことがありますのでご注意ください。
(Ankerというメーカーのものを愛用しているので推しております。)
片側が3.0、もう片方がType-Cというケーブルもありますが、両側USB Type-Cの方が高いw数で充電できますのでオススメです。ちなみにAmazonベーシックのものも販売されているようです↓
近年は、ワイヤレス充電器も存在しておりますが、w数が低いことがあります。低いと言っても10w-15wはあるようです。
複数購入予定で迷っている段階で調査した内容を執筆しました。
スプライン補間をRでしてみた:メモ
どうも、時々、医学系の論文でも出てくるスプライン補正ですが、実装してみました。
スプライン(Spline)補間はあるデータを多項式で補間する手法の1つです。データの点で区間を区切り、区間ごとに異なる多項式を使用して補間する手法です。
メモです。気になさらずに!w
n <- 3000
x <- seq(0, 1, length.out = n)
fx <- sin(6 * pi * x)set.seed(1)
y <- fx + rnorm(n, sd = 1.5)plot(x, y) # data
lines(x, fx, lwd = 2) # f(x)
legend("topright", legend = "f(x)", lty = 1, lwd = 2, bty = "n")
install.packages("npreg")
library(npreg)
mod.ss <- ss(x, y, nknots = 10)
mod.ssmod.smsp <- smooth.spline(x, y, nknots = 10)
mod.smsp
names(mod.ss)names(mod.smsp)
'sqrt(mean*1'"'sqrt(mean*2"
"sqrt(mean*3"
plot(x, y)
lines(x, fx, lwd = 2)
lines(x, mod.ss$y, lty = 2, col = 2, lwd = 2)
lines(x, mod.smsp$y, lty = 3, col = 3, lwd = 2)
legend("topright",
legend = c("f(x)", "ss", "smooth.spline"),
lty = 1:3, col = 1:3, lwd = 2, bty = "n")plot(mod.ss)
mod.sum <- summary(mod.ss)
mod.sum



PythonでBland-Altman plot(ブランドアルトマンプロット)を作成。
どうも、これまでRコマンダーとRでブランドアルトマンプロットを作成してきました。
今回は、
Pythonでブランドアルトマンプロット(Bland-Altman plot)を作成
前回の記事でも、少しふれましたが、ブランドアルトマンプロットは、二つの異なる検査、または、2人の異なる測定技術、1回目と2回目の検査間の測定値の違いを視覚化するために使用されます。
理学療法に関する論文だと、邦文ではこちらが詳しく書いております↓↓。
Bland-Altman分析を用いた継ぎ足歩行テストの検者内・検者間信頼性の検討
今回は、男前と女前2人の男女の検査間による誤差を視覚化したいと思います。
(ここは、無視して大丈夫です。)
import pandas as pd
import statsmodels.api as sm
import matplotlib.pyplot as plt
df = pd.DataFrame({'Otokomae': [10,20,20,5,4,1,20,5,60,6,0,6,60,6,60,0],
'Onnamae': [12,19,17,7,8,5,25,1,52,1,5,1,50,1,61,5]})
f, ax = plt.subplots(1, figsize = (12,8))
sm.graphics.mean_diff_plot(df.Otokomae, df.Onnamae, ax = ax)plt.show()
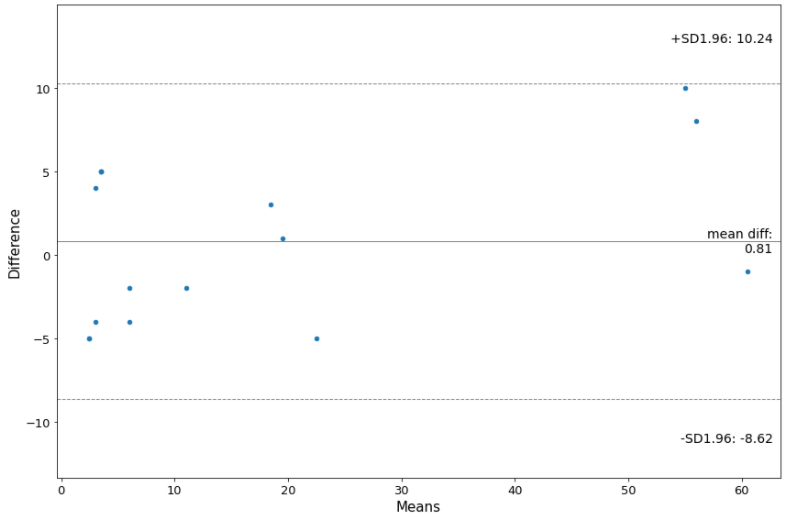
ブラアンドアルトマンプロットのX軸は、2人の平均測定値を表示し、y軸は、2人の間の測定値の差を示しています。
平均差:0.81
平均差の95%CI下限:-8.62
平均差の95%CI上限:10.24

 |
やさしいR入門 初歩から学ぶR-統計分析ー [ 赤間世紀 ] 価格:2,860円 |
![]()
![]()
Pythonで共分散分析(One-Way ANCOVA)をしてみた:Analysis of Covariance
どうも、お久しぶりです。
本日は、簡単に共分散分析(ANCOVA:Analysis of Covariance)をPythonで行いましたので記事にしてみました。
まず、分散分析(ANOVA)は、三つ以上の独立したグループの平均値に統計的に有意な差があるか否かを決定するために使用する検定です。例えば、
FIM移動項目(”自立”, "見守り", "介助")の3群では歩行速度に差があるか?
という解析を行いたいとします。
一般的には、自立が歩行速度が速くて、介助の方が遅いという解釈です。しかし、年齢というFactorがありますよね。歩行自立の方が年齢が若いかもしれません。この年齢が共変量(交絡)となっている可能性がありますよね。
この年齢という共変量を考慮して解析するのが、共分散分析(ANCOVA)です。先ほどの例で言うと、年齢を考慮しても、歩行速度に有意差があるのか?と言うことですね。
ANCOVAにはいくつかの前提条件があります。
・共変量と因子変数(群)は独立している
・分散の均一性
・独立性
・正規性
・極端な外れ値がない
これらの条件をクリアしていればANCOVAへGoです。
まずは、必要なものをインストール
pip install pingouin
import numpy as np
import pandas as pdfrom pingouin import ancova
データは適当です。(FIM、年齢、歩行速度)
df = pd.DataFrame({'fim_idou': np.repeat(['介助', '見守り', '自立'], 7),
'age': [67,88, 75, 77, 85,77,77,
92, 69, 77, 74, 88, 70,66,
96, 91, 88, 82, 80,67,56],
'gait_speeds': [0.8, 0.7, 0.6, 0.9, 0.4,0.3,0.5,
1.2, 1.4, 1.2, 1.9, 1.7,1.5,1.9,
1.0, 2.1, 1.5, 2.5, 2.8,1.9,2.0]})
結果を出力 !!!!
ancova(data=df, dv='gait_speeds', covar='age', between='fim_idou')
このような感じになりました。

FIM移動のp値は0.000016です。
年齢を考慮しても、歩行速度に差があったと言う解釈になります。
(どの群間に差があったかは、事後検定が必要です!)
別のコード
import pandas as pd
df >> group_by(X.group) >> summarize(n=X['bmi'].count(), mean=X['bmi'].mean(), std=X['bmi'].std())

import seaborn as sns
import matplotlib.pyplot as plt
fig, axs = plt.subplots(ncols=2)
sns.scatterplot(data=df, x="grip_strength", y="group", hue=df.group.tolist(), ax=axs[0])
sns.boxplot(data=df, x="knee_strength", y="group", hue=df.group.tolist(), ax=axs[1])
plt.show()

from pingouin import ancova
ancova(data=df, dv='knee_strength', covar='grip_strength', between='group')
握力を共変量にしたの膝伸展筋力の差の検定
前回の記事↓
|
やさしいR入門 初歩から学ぶR-統計分析ー [ 赤間世紀 ] 価格:2,860円 |
![]()
![]()
ブランドアルトマンプロット(Bland-Atman plot)をRで作成!!
どうも、お久しです。
前回は、RコマンダーでBland-Altman analysisを行いました。
これは、Rコマンダーなので基本的にクリックだけで統計解析できます。
たまに、Rコマンダーのエラーが出てしまうということでしたので、Rでブランドアルトマンプロット(Bland Altman plot)のコード作成しました。基本的にコピペで使えます。
まずは、パッケージのインストールから!!
install.packages("BlandAltmanLeh")
library(BlandAltmanLeh)
データは適当です。Aのところ、Bのところに、あなたのデータを入力してください!!朱色のところです。
df <- data.frame(A=c(2,5,6,5,5,4,5,5,5,5,5,5,45,4,5,6,5,4,5,5),
B=c(5,6,6,8,9,7,5,6,54,5,2,3,2,1,5,6,8,6,6,5))
おまじないです。(すみません)
df$avg <- rowMeans(df)
df$diff <- df$A - df$B
mean_diff <- mean(df$diff)
mean_diff
95%信頼区間の上限と下限
lower <- mean_diff - 1.96*sd(df$diff)
lowerupper <- mean_diff + 1.96*sd(df$diff)
upper
ggplotですね。
library(ggplot2)
あとはプロットですね!!
ggplot(df, aes(x = avg, y = diff)) +
geom_point(size=2) +
geom_hline(yintercept = mean_diff) +
geom_hline(yintercept = lower, color = "blue", linetype="dashed") +
geom_hline(yintercept = upper, color = "blue", linetype="dashed") +
ggtitle("Bland-Altman Plot") +
ylab("Difference Between Measurements") +
xlab("Average Measurement")
適当なデータなので、偏りましたw

詳しい内容はこちら↓
RコマンダーでBland-Altman analysis (ブランドアルトマン分析) - 人工知能・リハビリ・日記・理学療法
↓ NRIとIDI : C統計量(AUC)では不十分??
|
やさしいR入門 初歩から学ぶR-統計分析ー [ 赤間世紀 ] 価格:2,860円 |
![]()
![]()
検査の反応性;Effect SizeとStandardized Response Mean(SRM)の話
どうも、お久しぶりです。
今年はアクセプトの確率50%です(分母が小さいです)。すみません。
Effect Sizeの話(Effect Size;効果量)
これよく聞くはなしですよね?論文に馴染みのない方は初耳かもしれません!
統計用語集にはこのような記載がありました。
ちなみに、理学療法士協会のHPにはこんな記載が....↓
難しい??ですよね。
臨床場面におけるアウトカム指標というのは、信頼性・妥当性・反応性が高いものでなければならないと言われております。
Responsiveness and validity in health status measurement: a clarification.
信頼性が高い評価というのは、1回目の2回目の測定が同じ傾向にあるというものです。これには、ICCとかκ係数などがあります。妥当性は、その計測された数値が意図したものを測定できているかというものですよね。これには、ROC曲線や回帰分析、相関によって評価されます。
反応性には、内部反応性と外部反応性があります。今回は、内部反応性についてです。
t検定
これも反応性の一つのようです。ただ、これは、2つの測定値に変化がないという仮説に基づく検定ですよね。t値が1.96より大きい場合は、いわゆる有意差ありということになって、反応したという解釈となります。ただこれは、サンプルサイズなどに依存するので、反応性を評価するための指標としては微妙ですよね。
Effect Size;効果量
Cohenさんによって最初に提案されたのが、効果量のようですね。Cohenさんらの有名な書籍はこちら↓(よく論文で引用されている書籍です。)
←ハードカバー
この効果量の計算方法は、初期と最終アウトカムスコアの平均差を初期の標準偏差で割ったものです。これは反応性の指標として推奨されているようですね。そして、Effect Sizeですが、Cohenさんによって小0.2-中0.5-大0.8という感じでに分かりやすいように分類?されています。つまり、
0.2は、ベースラインの標準偏差の20%の変化
0.5は、ベースラインの標準偏差の50%の変化
0.8は、ベースラインの標準偏差の80%の変化
ということになります。
Standardized Response Mean(SRM);標準化反応平均
これも良く使用されている指標ですよね。少し前の研究ですが、Strokeという有名なジャーナルでも脳卒中後の運動機能の反応性についてSRMを使用していました。
論文:https://www.ahajournals.org/doi/10.1161/STROKEAHA.108.530584
他にも、慢性脳卒中患者のバランスや歩行のアウトカムの反応性としても使用されています。論文:https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6136166/
このSRMの計算方法は、”スコアの平均変化を変化したスコアの標準偏差で割る”という計算です。普通の割り算なので特に統計ソフトも必要ありませんね。SRMについても、Cohenの基準をもとに小-大に分類?されているようです。
その他には、MCID(外部反応性)などの指標も反応性の一部のようです。(また今度まとめてみたいde
すね-。)
つまり、言い換えれば、観察された測定値の変化は、患者の状態における重要な変化を反映していない可能性があるということです。ということであれば、信頼性と妥当性の概念は2つに完全に分類できるものではないですよね。そして、完全な信頼性と妥当性というものないようです。
https://pubmed.ncbi.nlm.nih.gov/7550178/
ややこしくなってきました。反応性や信頼性は思ったより奥が深いようです。
やはり、内的反応性だけでは不完全なので、反応性の研究を行うときは外的反応性も同時に検証すべきですね。